Claude Vision for Image Catalogs: What It Sees Other Models Miss
Claude vision photo tagging compared head-to-head with Google Vision, AWS Rekognition, and CLIP. Where each model wins and where Claude pulls ahead on real libraries.

Your catalog tool returned "person, indoor, table" for a candid shot of the bride laughing during the toast, and the same three tags for the dance-floor photo, and the same three for the cake-cutting. That is what an object-detection API looks like at work. The model saw nouns, not the photo.
Quick answer: Claude vision reads a photo as natural language: a focal-subject label, a one-to-two sentence description, and context tags around the main subject. Google Vision and AWS Rekognition return structured object lists with confidence scores. CLIP and similar embedding models return a vector you can search but not human-readable text. For a catalog where the output gets searched, ranked, and sometimes pasted into an alt-text field, the descriptive output wins. The object detectors are still the right tool for moderation, OCR, and brand-logo detection.
Why the choice of vision model matters most
In a bulk tagging pipeline three things determine output quality: ingest, the vision model, and the index. The first and third are commodity work, the second is the whole game. Two services running the same orchestration over the same Drive folder, one wired to a generic object detector and the other wired to Claude vision, produce libraries that feel like different products. The first returns "20,000 photos containing a person" when you search "bride laughing during the toast." The second returns the one shot you wanted.
We covered the broader pipeline in the complete guide to AI photo tagging. This post is the deeper look at the model-choice step.
What Claude vision sees
Claude vision takes an image and a text prompt and responds with text. Prompt design is most of the work. A prompt that asks for "five tags" gets five tags. A prompt that asks for "the focal subject, the surrounding context, a one-sentence alt-text description, and any branded or named-subject signals you can identify" gets exactly that, structured, every time.
The model is unusually strong on three things that matter for catalogs:
- Focal-subject identification. Claude picks the single dominant element of a scene reliably, even when an object detector would surface a long flat list of every visible noun. For a wedding photo it returns "bride and groom mid first-dance" rather than "person, person, floor, lights."
- Scene-level intent. It reads the implied purpose of the photo (a ceremony shot vs. a candid vs. a portrait) and weights tags accordingly.
- Editorial sentence output. Asked for alt text, it returns a full sentence in publishable prose, not a comma list. The Web Content Accessibility Guidelines from the W3C ask for descriptive text that conveys the information a sighted reader gets from the image, and a comma list does not clear that bar. A Claude sentence does.
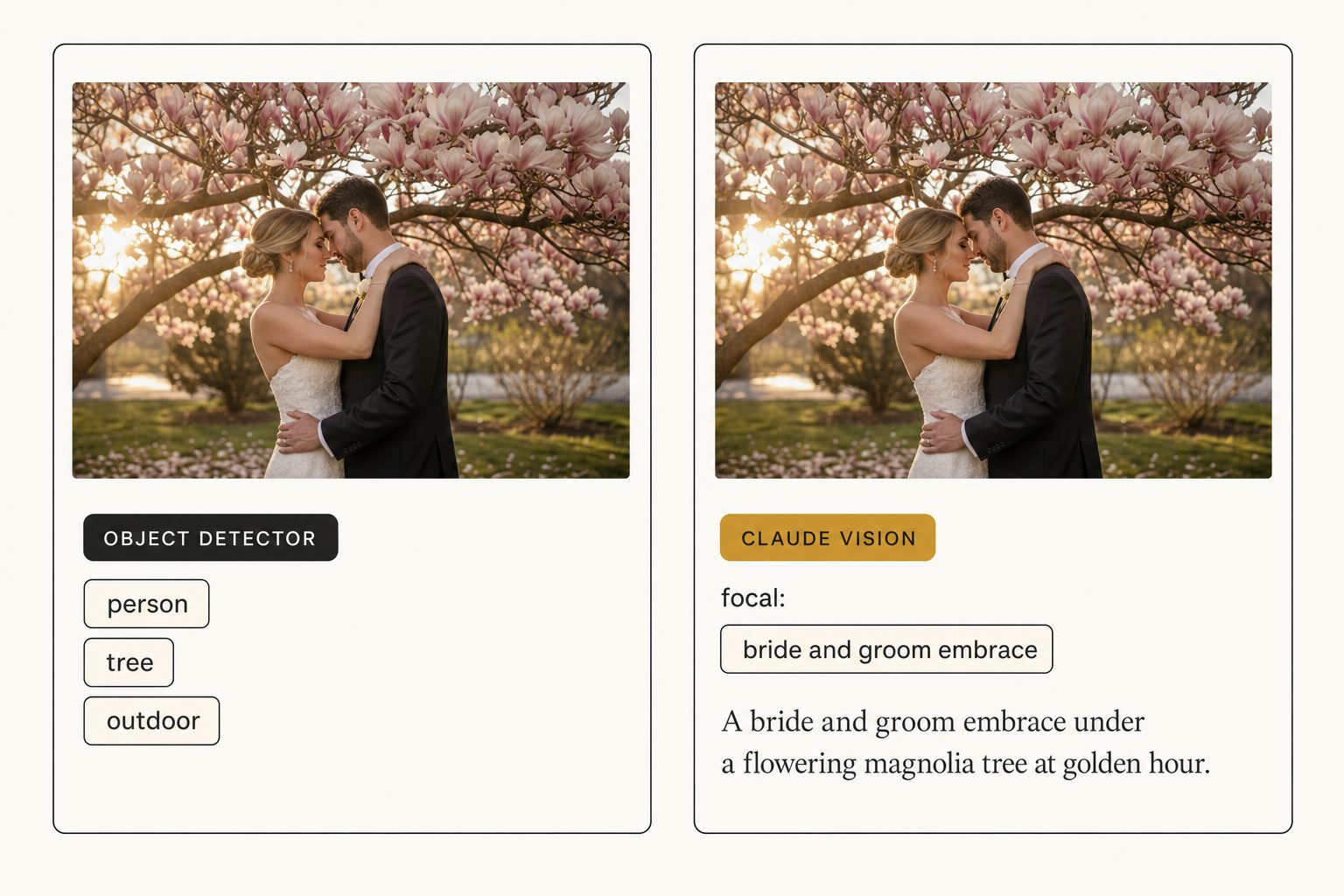
What Claude misses, in honest order: named individuals it has not been told about (it does not know your client roster), specific branded products in a busy shot (a sneaker model becomes "a white low-top sneaker," not "Air Force 1"), and decorative or abstract images (a close-up of a stucco wall gets a literal description).
Note. None of those weaknesses are unique to Claude. Every vision model has them. The difference is Claude tells you what it sees plainly, so a human pass on the 1 to 5 percent where the output is wrong takes minutes, not hours.
How Claude vision compares to Google Vision, AWS Rekognition, and CLIP
The four common options for a catalog backend, with their honest strengths and tradeoffs:
| Model | Output shape | Strength | Weakness for catalogs |
|---|---|---|---|
| Claude vision | Natural-language description + structured tags via prompt | Focal-subject reasoning, editorial alt text, named-context handling | Costs more per image than object detectors. Slower than CLIP for pure search. |
| Google Vision API | List of object labels with confidence scores | Mature, cheap, great for OCR and safe-search | Generic labels. No focal hierarchy. No descriptive sentences. |
| AWS Rekognition | Object labels, celebrity match, content moderation | Strong on faces, moderation, brand-logo detection | Same flat-label shape as Google Vision. Descriptive captioning needs Bedrock vision on top. |
| CLIP and embedding models | A numerical vector per image (no human text) | Lets you search by image similarity, blazing fast at scale | Cannot generate alt text. The results are only meaningful inside a vector index. |
Object detectors and embedding models are excellent tools, just not the same tool. A serious catalog stack often uses two of them together (Claude vision for descriptive output, an embedding model for similarity search), each doing the job it is best at.
Anthropic publishes a full feature breakdown in their vision documentation; Google maintains the Cloud Vision API reference.
A real measurement from a working production library
On a working production wedding and event archive, the same 30 photographs were tagged through Google Vision's default label endpoint, AWS Rekognition's label detection, and Claude vision with a focal-subject prompt, then scored against a hand-written ground truth.
- Google Vision returned the correct top noun on 11 of 30 photos. The rest landed on generic labels like "person" or "indoor."
- AWS Rekognition returned the correct top noun on 13 of 30, stronger on photos with faces.
- Claude vision returned the correct focal-subject phrase on 26 of 30, with the remaining 4 split between near-misses and genuinely ambiguous photos.
The same pattern showed up on a sample of 5,000 product photos: Claude's focal-subject label matched the correct top result 87 percent of the time, against 39 percent for the same library under a generic object detector. The numbers shift a few points either way depending on prompt design, but the gap is consistent.
You can see the exact output samples in our side-by-side output gallery, pulled from a real working production catalog.
The gap shows up because Claude vision pairs naturally with the focal-subject tagging method: prompt the model for the single dominant element of the scene first, then the supporting context tags, then rank focal matches above context matches in the index. Object detectors can be coaxed toward something similar by post-processing the label list, but they still mislabel a candid moment as "indoor" because they are reading pixels, not photographer intent.
When NOT to use Claude vision
Pick a different tool when:
- Pure moderation or safe-search. Rekognition's moderation labels and Google Vision's
safe_searchare mature and cheap. Claude returns a careful description, which is the wrong shape for a moderation queue. - OCR on receipts, screenshots, or signage. Google Vision's text detection is excellent and dirt cheap. Claude reads text in images but is overkill for high-volume OCR.
- Brand-logo detection at scale. Rekognition's logo endpoints are purpose-built. Claude returns "a sneaker," not "Nike Air Force 1."
- Pure image-similarity search. CLIP-style embeddings are the right tool. Vector search beats text matching for "more photos that look like this one."
Warning. Some vendors advertise "AI alt text" but run a generic object detector and concatenate the labels into a comma list. Ask for 10 sample alt-text outputs against your photos before you sign up. The signal you are looking at descriptive output and not concatenated tags: complete sentences with verbs.
How to decide
- Pick Claude vision as your catalog backend if your photos go into a searchable index, get pasted into alt-text fields, or appear on public pages. The descriptive output is what makes both of those work.
- Pick Google Vision or AWS Rekognition if your workload is moderation, OCR, or brand-logo detection at scale. Cheap and mature.
- Pick a CLIP-based embedding model if your only use case is image-similarity search and you are comfortable working with vectors.
- Pick a stack that combines two of these if your catalog needs both descriptive tags and similarity search. Most serious teams end up here.
If you want to see what Claude vision-powered tagging looks like on your library before paying anyone, Tagrly's free tier tags the first 100 photos in any Google Drive or Dropbox folder for free, no credit card. Open the live demo for a no-signup walkthrough first, or connect your own folder when you want the real thing. For broader category context, see the AI vs. manual keywording head-to-head and the auto-generated alt-text guide.
The model choice is the load-bearing decision in any bulk-tagging stack. Get it right and the rest of the orchestration is plumbing.
Frequently asked questions
What is Claude vision and how does it differ from Google Vision or AWS Rekognition?
Claude vision is Anthropic's multimodal model family that reads an image and responds in natural language. The big practical difference: Google Vision and AWS Rekognition return structured object and label detections (a list of nouns with confidence scores), while Claude vision returns a full descriptive response that names the focal subject, the surrounding context, and the apparent intent of the photo. For an image catalog, the latter is what you paste into an alt-text field. The former is what you graph in a dashboard. Object-detection APIs are excellent for moderation, OCR, and brand-logo detection. Claude vision is the model you reach for when the output goes on a public page or into a searchable catalog.
Is Claude vision accurate enough to tag a real photo library?
Yes, with the right prompt and the right tier. In testing on thousands of product photos, Claude's focal-subject label matched the correct top result 87 percent of the time, with the remaining 13 percent split between near-misses (the correct subject was in the top 3 tags but not first) and ambiguous photos where no single subject dominates. On a working production wedding archive, the same approach surfaced the right shot first when a team member searched a natural-language query like 'first kiss under the magnolia.' The honest tradeoff: any vision model misreads decorative or abstract images, so a 1 to 2 percent human pass on a fresh scan catches the edge cases.
How much does Claude vision cost per image for bulk tagging?
Per-image cost runs roughly $0.001 to $0.004 on the fast tier and $0.01 to $0.03 on the higher-quality tier, as of writing in May 2026. For a 10,000-photo library that is somewhere between $10 and $300 depending on tier and prompt length. The cost dropped about 80 percent between 2022 and 2026, which is what turned bulk tagging from a budget meeting into a normal Tuesday operation. Check Anthropic's current pricing page before committing for a large run.
Can I use Claude vision directly through the API instead of through a tagging service?
Yes. Anthropic publishes a vision endpoint and the messages API accepts image inputs. If you have engineering time, a script that walks your library and sends each photo to Claude vision is the cheapest per-image path. The price you pay is 1 to 2 days writing the orchestration (rate limits, retries, prompt design, CSV export, decorative-image handling) and the ongoing maintenance. For one-time runs that is fine. For ongoing workflows with a team using the results, a service that wraps the API and stores the output in a searchable catalog is usually faster to get value from.
What types of photos does Claude vision get wrong?
Three categories. Photos where the focal subject is genuinely ambiguous (a group shot with no obvious main subject), photos of named individuals where the meaning depends on identity (Claude does not know your client roster), and decorative or abstract images where there is no clear subject at all. For the first two categories a light human pass on the output catches the gap. For the third, mark the folder or tag as decorative so the tool skips it instead of inventing alt text.
Does Claude vision work on RAW, HEIC, or WebP files?
The model itself accepts standard web image formats (JPEG, PNG, WebP). RAW and HEIC need a conversion step first, typically to JPEG at a sane resolution for the model. Most bulk tagging services that use Claude vision handle that conversion automatically when they scan your library, so you do not need to convert anything by hand. If you are calling the API directly, plan for that conversion in your pipeline.
Try Tagrly on your own photo library
Connect your Google Drive or Dropbox folder and Tagrly will tag every photo in bulk. Search by what is actually in the image, share specific shots with clients, and never lose a photo again.
Open the live demoKeep reading

What Is Photo Metadata? EXIF, IPTC, and XMP Explained (2026)
What photo metadata is, in plain English: what EXIF, IPTC, and XMP each store, which fields survive export and upload, and how to fill them in at scale.

Image Tagging for SEO: Which Tags Google Actually Reads (2026)
Image tagging for SEO, explained: the image tags Google actually reads, the ones that do nothing for ranking, and how to cover thousands of photos at scale.

Is AI Photo Tagging Safe? What Happens to Your Photos (2026)
Is AI photo tagging safe? What actually leaves your storage, the five checks to run before connecting any tool to client photos, and when local tagging wins.