How Fast Is AI Photo Tagging on a 100,000-Photo Library?
How fast is AI photo tagging? Real throughput numbers: photos per hour, what slows a scan down, and how a 100,000-photo library behaves end to end.

You point a tagging tool at a Drive folder with 100,000 photos in it, hit scan, and then you want to know one thing before you commit: is this done in an hour, or is it a three-day job that pins your computer? That question, how fast is AI photo tagging on a library that size, has a real answer, and it is more reassuring than most people expect.
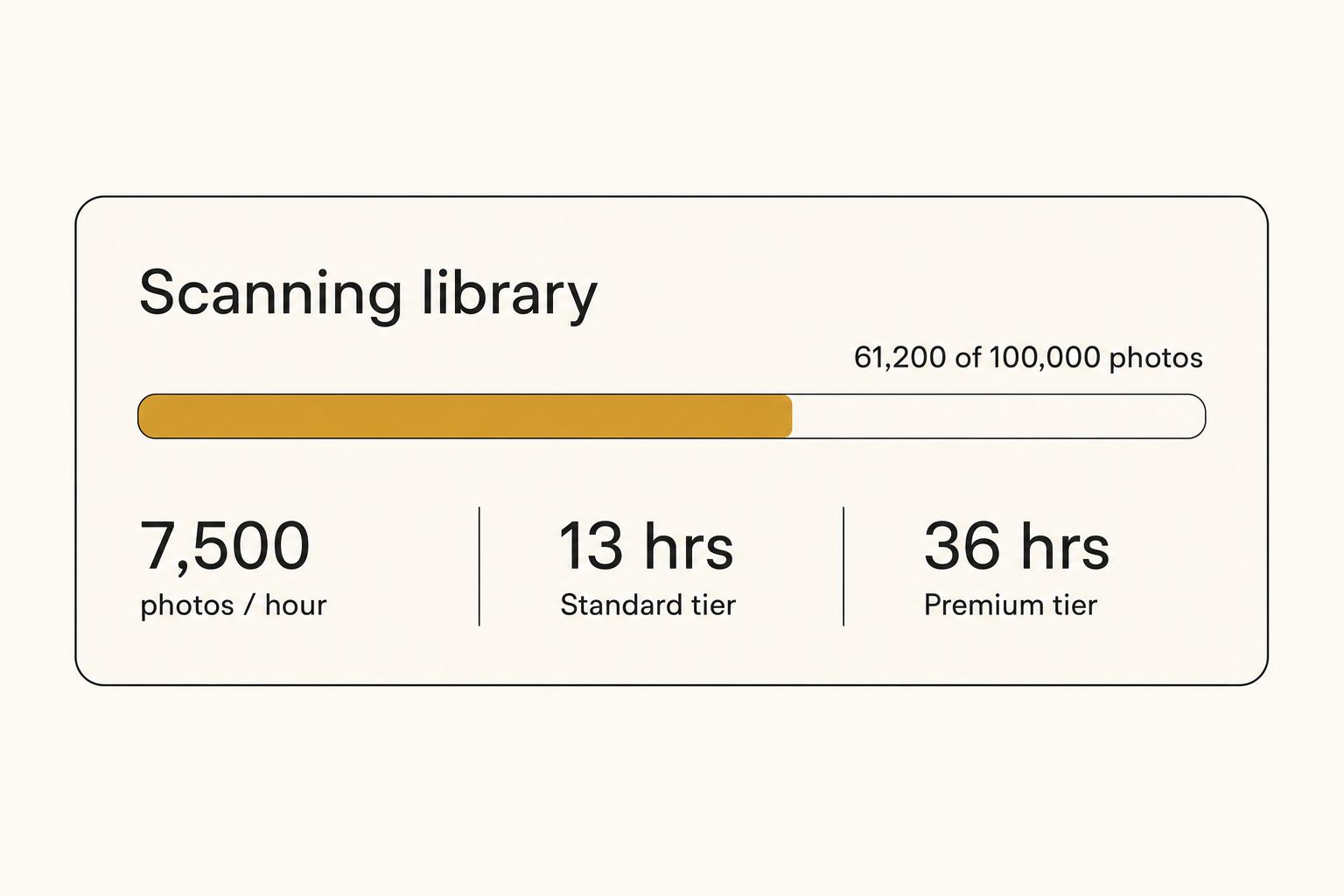
Quick answer: AI photo tagging runs at roughly 5,000 to 9,000 photos per hour on a fast structured-tag tier and 2,500 to 3,000 per hour on an editorial alt-text tier. A 100,000-photo library finishes in about 13 hours on the fast tier and about 36 hours on the editorial tier, end to end. The vision model is the bottleneck, not your internet or the storage API, and you only pay the big number once: after the first scan, only new or changed photos get re-tagged.
How fast is AI photo tagging, in photos per hour
Speed in this category is best measured in photos per hour, because that is the number that scales with your library. Here is the honest range, drawn from running real archives rather than a benchmark folder.
| Library size | Standard tier (structured tags) | Premium tier (editorial alt text) |
|---|---|---|
| 1,000 photos | about 8 minutes | about 22 minutes |
| 10,000 photos | about 80 minutes | about 3.7 hours |
| 100,000 photos | about 13 hours | about 36 hours |
The fast tier lands around 7,500 photos per hour once a scan is warmed up and running requests in parallel. The editorial tier is roughly a third of that, because each photo gets a longer vision pass that writes full descriptive sentences instead of short tags.
For a concrete reference point: a working production library of about 19,000 wedding and event photos finished its first complete overnight scan in roughly 9 hours. That early run was deliberately conservative, with a mix of editorial-grade passes and cautious rate limiting, so it ran slower than a pure structured-tag scan would today. Extrapolated honestly, it tells you a 100,000-photo library is an overnight-to-weekend job, not a coffee-break one.
Note. Ignore any tool that quotes a "photos per second" number from a tiny demo folder. Throughput on the first ten photos is meaningless. What matters is the sustained rate across tens of thousands of images, which is always lower because of rate limits and retries on the occasional slow request.
What actually dominates the scan time
Most people assume downloading 100,000 photos is the slow part. It is not. Reading one photo from Google Drive or Dropbox takes a fraction of a second, and a tagger reads many photos in parallel, so storage is a thin slice of the total.
The vision pass is what governs the pace. Generating tags and alt text for a single photo takes one to a few seconds, depending on the tier, and that step repeats once per photo. So the total time is almost entirely "number of photos times per-photo vision time," divided by how many vision requests the tool can run at once.
That gives you three levers, and only three:
- Tier. Structured tags are roughly 3 times faster than editorial alt text. This is the biggest single lever you control.
- Parallelism. How many vision requests the tool fires at the same time, capped by the model's rate limit.
- Library size. The one variable you cannot change, but the one the other two are measured against.
Network speed, your laptop, and which storage provider you use barely move the number. We go deeper on why the model choice matters most in our guide to what Claude vision sees that other models miss.
Standard tier vs Premium tier: the speed tradeoff
The single biggest factor in how fast your scan finishes is which output you ask for. The two tiers are built for different destinations.
The Standard tier produces short structured tags meant for internal search: "outdoor wedding, sunset, magnolia tree, candid." It is fast because the vision pass is short and the output is compact. This is the tier you run across the whole library so every photo becomes findable.
The Premium tier produces editorial-grade alt text, full sentences you can paste straight onto a public page: "A bride and groom embrace under a flowering magnolia tree at golden hour, surrounded by family seated on white folding chairs." That quality costs time, because the vision pass is longer and more deliberate.
Tip. You almost never need Premium across the entire library. Run Standard on everything for search, then run Premium only on the 5 to 10 percent of photos headed for a website, portfolio, or press release. That keeps your big scan on the fast tier and your editorial budget small. The side-by-side output on our output quality comparison shows exactly what each tier returns for the same photo.
Because most teams split this way, the realistic timeline for a 100,000-photo library is closer to the 13-hour Standard number than the 36-hour Premium one. You are running the fast tier on the whole thing and the slow tier on a sliver.
Rate limits and why parallelism is capped
Vision models enforce a rate limit: a ceiling on requests per minute. A well-built tagger runs right up against that ceiling and no further, fanning out many photos at once, then backing off and retrying when it hits the cap. This is why "just run more in parallel" is not infinite free speed. Past a point, more parallel requests get throttled, the tool waits, and throughput plateaus. The published numbers above already assume the tool runs near the rate-limit ceiling. You can read more about how the underlying model handles image inputs in Anthropic's vision documentation.
Storage providers have rate limits too, but they are generous. The Google Drive API reference and the Dropbox data-ingress guide both allow comfortably more parallel reads than the vision model can keep up with, so storage almost never becomes the bottleneck. The vision rate limit is the real ceiling, and it is the same whether your photos live in Drive or Dropbox.
Incremental re-scans: you only pay the big number once
The overnight scan sounds intimidating until you understand that it happens exactly once. After the first full pass, a good tool never re-tags a photo it has already seen.
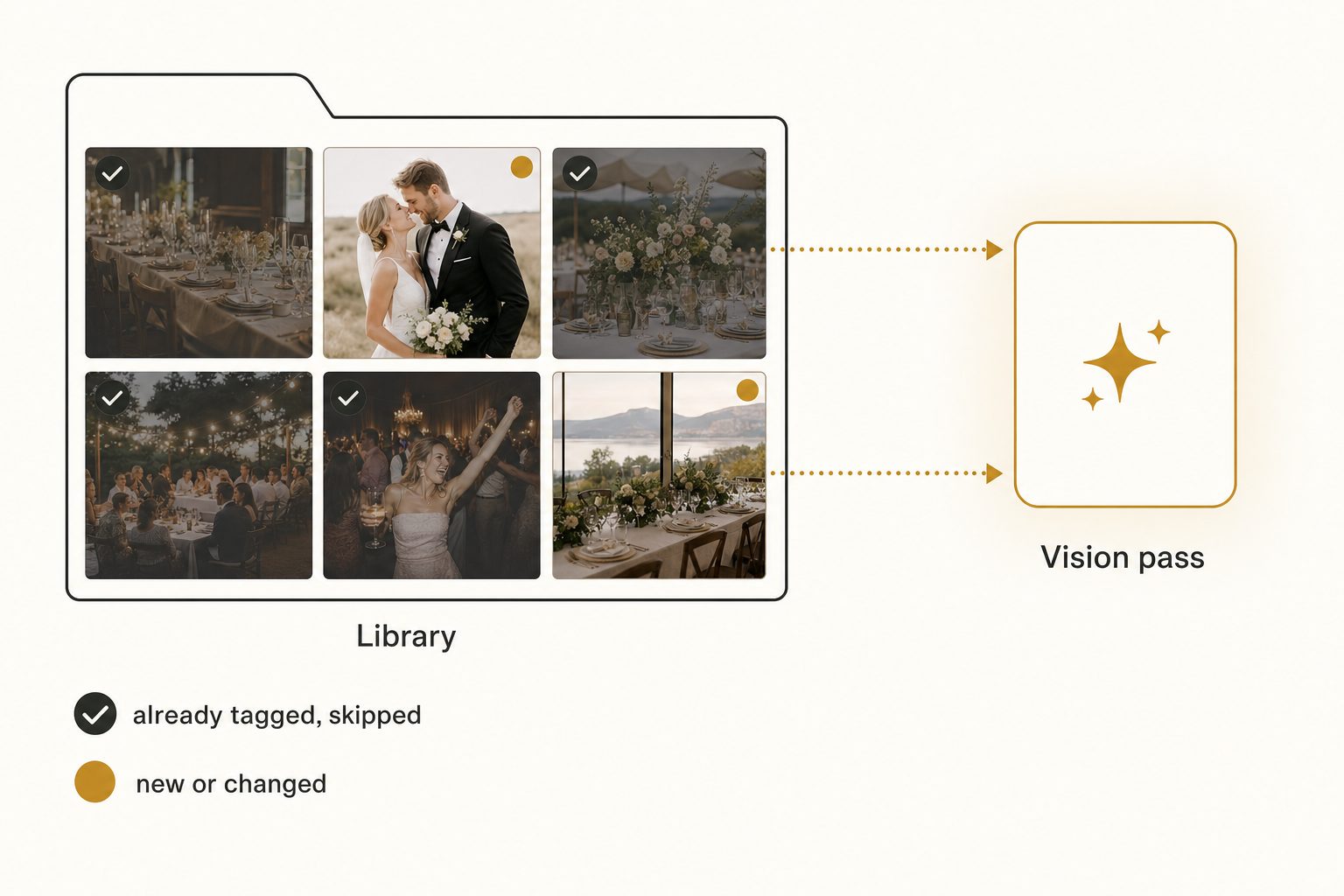
During ingest, the tool records a content hash for every photo, a short fingerprint of the file's pixels. On the next scan it walks the library again, recomputes the hashes, and compares. Anything it has already tagged gets skipped instantly, and only files that are new or changed go through the vision pass.
So adding 500 photos to a 100,000-photo library means tagging 500 photos, which finishes in minutes. The math is simple:
- First scan: every photo runs the vision pass. This is the 13-hour Standard or 36-hour Premium number.
- Every scan after: only new or changed photos run the vision pass. Usually minutes.
This is also why you can use the library while it is still tagging. Each photo becomes searchable the moment its vision pass writes to the database, so the catalog fills in progressively rather than appearing all at once at the end. Your originals never move out of Google Drive or Dropbox at any point.
How that compares to tagging by hand
Speed only means something next to the alternative. A skilled human keyworder, typing into Lightroom or Bridge at editorial depth, produces 100 to 200 photos per hour, so a 100,000-photo library is roughly 667 hours of human work. AI bulk tagging does that same library in 13 to 36 hours of unattended machine time, with nobody at the keyboard.
That is the gap: hundreds of hours of paid attention versus a scan you start before you leave on Friday. The AI also wins on consistency, because one model uses the same vocabulary across the whole library, where two human keyworders rarely choose the same words for the same photo. We break down the quality side of that tradeoff in AI photo tagging vs manual keywording.
Tip. If you want to feel the speed on your own photos instead of trusting a table, try it on a sample folder. Tagrly's free tier tags the first 100 photos in any Drive or Dropbox folder, no credit card, so you can watch the throughput on your real images before deciding anything.
So, how fast is AI photo tagging for you?
For most teams the honest answer is: the first scan of a large library is an overnight or weekend job, and everything after that is minutes. A 100,000-photo library lands around 13 hours on the fast structured-tag tier and around 36 hours if you run editorial alt text across the whole thing, though almost nobody should do the latter. Run Standard on everything, Premium on the public-facing sliver, and start the scan when you are about to step away.
The bottleneck is the vision model, not your connection or your storage, so Drive and Dropbox finish in about the same time. And because re-scans only touch new or changed photos, you pay the big number exactly once. If you want a real feel for the throughput, the fastest way is to point Tagrly at a folder and watch the first hundred photos tag themselves, then read the complete guide to bulk AI photo tagging for the full picture of how the category works.
Frequently asked questions
How long does it take to AI-tag 100,000 photos?
On a fast structured-tag tier, plan for roughly 13 hours for 100,000 photos, end to end, including reading each photo from storage, the vision pass, and writing results to a searchable database. On an editorial alt-text tier it is closer to 36 hours because each photo gets a longer, higher-quality vision pass. Both are overnight or weekend jobs you start and walk away from. As a real reference point, a working production library of about 19,000 wedding and event photos finished its first full overnight scan in roughly 9 hours on a conservative early run. The practical takeaway: a 100,000-photo library started Friday night is a fully searchable catalog by Saturday or Sunday.
What slows an AI photo tagging scan down the most?
The vision model is the bottleneck, not your internet connection and not the storage provider's API. Reading a photo from Google Drive or Dropbox takes a fraction of a second; generating tags and alt text for it takes one to a few seconds depending on the tier. So total time scales almost entirely with how many photos you have and which tier you picked, not with where the photos live. The two things that actually move the number are tier (structured tags are roughly 3 times faster than editorial alt text) and how aggressively the tool is allowed to run vision requests in parallel against the model's rate limit.
Is AI photo tagging faster on Dropbox or Google Drive?
It is roughly the same. Dropbox tends to return a full-resolution image slightly faster per request, while Google Drive's API allows generous parallel reads, so the two even out over a large library. Either way, storage read time is a small slice of the total. The vision pass dominates, so a 100,000-photo library takes about the same wall-clock time whether it lives in Drive or Dropbox. Pick whichever your photos are already in instead of moving them to chase speed.
Do I have to re-scan my whole library every time I add photos?
No. A good tool records a content hash for every photo it has already tagged, so on the next scan it skips everything it has seen and only runs the vision pass on new or changed files. Adding 500 photos to a 100,000-photo library means tagging 500 photos, not 100,500. That incremental scan finishes in minutes, not hours. This is why the big overnight number only happens once. After the first full pass, ongoing scans are cheap and fast.
Can I use my library while it is still being tagged?
Yes. Tagging writes results photo by photo, so a photo becomes searchable the moment its vision pass finishes, while the rest of the library is still in the queue. You do not have to wait for the whole scan to complete before searching. On a large first scan you will see the catalog fill in over the hours, with the photos at the front of the queue searchable first. Your originals stay in Google Drive or Dropbox untouched the entire time.
How does AI photo tagging speed compare to doing it by hand?
It is not close. A skilled human keyworder produces 100 to 200 photos per hour at editorial depth, so a 100,000-photo library is 500 to 1,000 hours of manual work. AI bulk tagging does the same library in 13 to 36 hours of unattended machine time, with no human sitting at a keyboard. That is roughly 30 to 60 times faster, and the AI output is internally consistent, which manual keywording across multiple people never is. The honest tradeoff is a light human review pass on the small fraction of photos the model misreads.
Try Tagrly on your own photo library
Connect your Google Drive or Dropbox folder and Tagrly will tag every photo in bulk. Search by what is actually in the image, share specific shots with clients, and never lose a photo again.
Open the live demoKeep reading

What Is Photo Metadata? EXIF, IPTC, and XMP Explained (2026)
What photo metadata is, in plain English: what EXIF, IPTC, and XMP each store, which fields survive export and upload, and how to fill them in at scale.

Image Tagging for SEO: Which Tags Google Actually Reads (2026)
Image tagging for SEO, explained: the image tags Google actually reads, the ones that do nothing for ranking, and how to cover thousands of photos at scale.

Is AI Photo Tagging Safe? What Happens to Your Photos (2026)
Is AI photo tagging safe? What actually leaves your storage, the five checks to run before connecting any tool to client photos, and when local tagging wins.